 �@�@
�@�@
�y�摜���N���b�N����Ɗg�債�܂��z
��N��11����PC��Windows7�ɃA�b�v�O���[�h�������Ƃɔ����A���[���\�t�g���@Outlook2010���g�p���邱�ƂɂȂ����̂����A����ȍ~
���X��M���[���������������邱�ƂɋC���t�����B�@�i���̉摜�j
�s�v�c�Ȃ��ƂɃv���r���[�ʼn����Ȃ��̂ƁA�p������OK�Ȃ̂Ŋ������̑�����ʂ��ĕ\������u�_�u���o�C�g�����v�ɖ�肪����ƍl���A����
���}�C�N���\�t�g����̃A�b�v�f�[�g�ʼn������邾�낤�ƕ��u���Ă����B
�R���Ȃ���A�ŋ߂�iPhone, Exchange Server, ���̑�����̔��M������̃��[���ŕ������������������u�ł��Ȃ��Ȃ��ė����B
�������@�͕������邪�A�ǂ������̎g�p���Ƀ}�b�`���Ȃ��B
�������@�P�GOffice2010�����ŐV�������[���z���_���쐬���č���̐V�������[���͐V�����z���_�Ŏg��
������Outlook2003����ڍs�������[���z���_�ƕ�������Ă��܂��̂Ŏg���Â炢�@�i�p���j
�������@2
; Internet Explorer �̃Z�L�����e�B�X�V�v���O���� (KB2467659) ���C���X�g�[������B
�������c�O�Ȃ���u���̍X�V�v���O�����͂��g���̃R���s���[�^�ɂ͎g���܂���v�@���o�͂���g�p�ł��Ȃ��B�i�p���j
�d�����Ȃ��̂ŁA��M���[���̃G���R�[�h�����ʐ^�̗l�ɕύX���Ă݂������ς�炸�ʖځI
���ꂱ��G���R�[�h�����������Ă�����ɁA�ˑR��������ʂ��\�����ꂽ�B�E�E�E���āA�����łǂ�������̂�������Ȃ��H�H�H
�ēx�A�ʂ̉����������[�����g���ā@Try & Error ��Ƃ��J��Ԃ��B�@===>�������I�I
�菇�͂������B
�@ �����Ă��郁�[�����J���u���b�Z�[�W�v�^�u���N���b�N�B
�A �ړ��{�b�N�X�́u�A�N�V�����v�A�C�R�����N���b�N
�B �u���̑��̃A�N�V�����v���N���b�N
�C �u�G���R�[�h�v���N���b�N����Ɓ@���{��(�����I��),UTF-8, UTF-7,���̑�(M)���X�̃G���R�[�h�p�^�[�����\�������B
�D 1���; �����[���b�p(Windows) ��I������B
�E 2���; ��L�@����C���̑����������x�s���A�G���R�[�h��[UTF-8]�ɐݒ肷��@�������������\������܂��B
�F ���̃��[���𐳂����㏑�����ۑ�����ׂɁA�@�t�@�C���[�㏑���ۑ��@���s�Ȃ��B
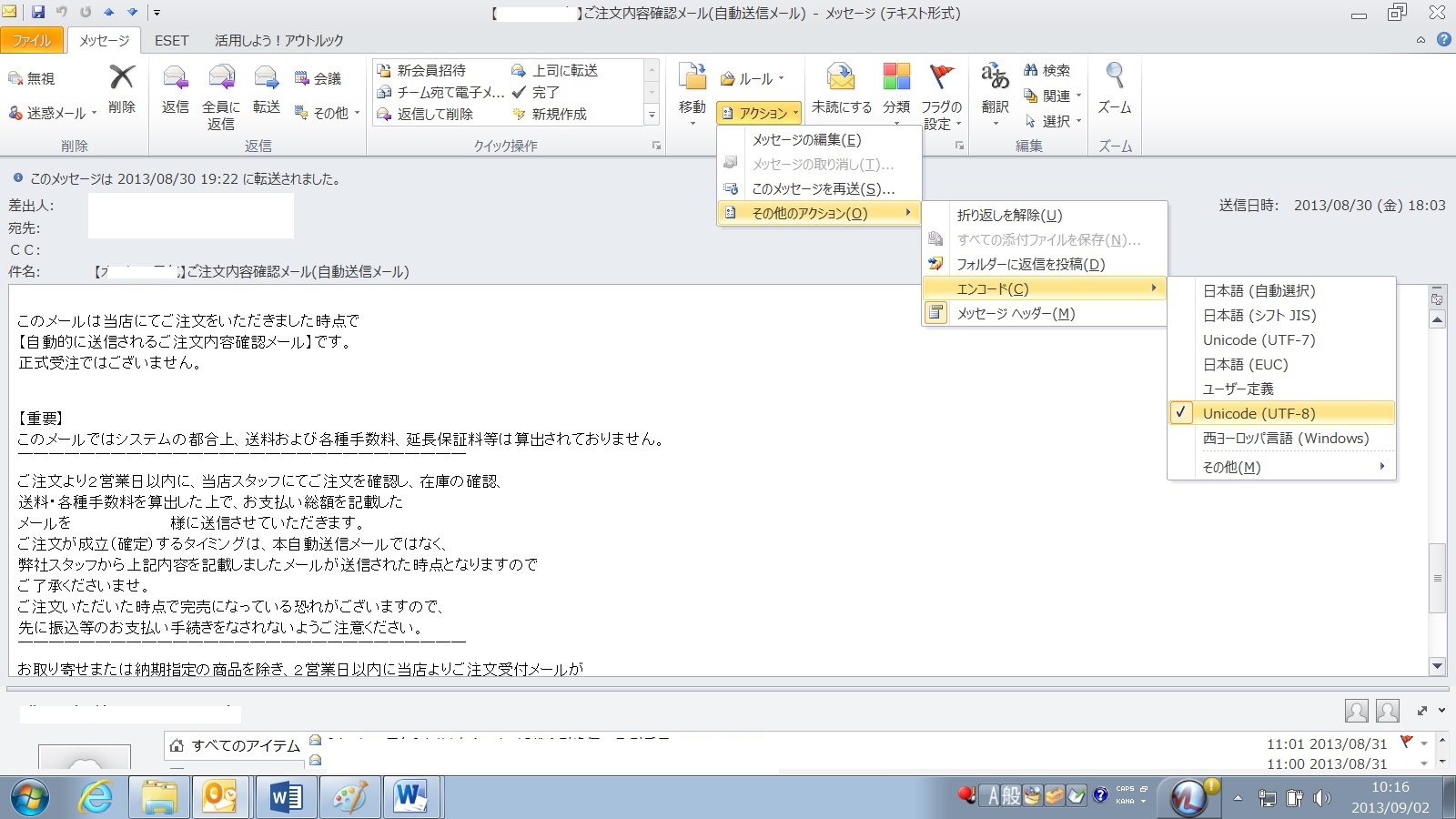
����ŁA���������[���͏㏑�������̂Ŏ���͐������ǂނ��Ƃ��o���܂����S���_���I�Ŗ����̂ō���܂��B
�{���́A��M�����_�u���o�C�g����L�����N�^�[���ʂ̕s�����}�C�N���\�t�g�ɏC�����Ă����Ȃ��Ƃ����Ȃ��̂ł����A��芸������OK�̗l�ł��B
��ŁA�C���V�f���g���グ�邱�Ƃɂ��܂��B�@�������A��L�́u�������@�P�v�ł��Ȃ����Ɖ��ꂽ�獢���Ă��܂��܂��B
�y2013.09.04�NjL�z
�}�C�N���\�t�g�̃T�|�[�g�f�X�N�ɓd�b�����܂����B
����������Ƃ���A��͂��L��[�������@1]�̒ʂ�AOutlook2010�ŐV���Ƀ��[���z���_���쐬���āAOutlook2003�ō쐬�����z���_
���C���|�[�g���Ȃ���Ȃ�Ȃ��Ƃ̂��Ƃł����B�@���R��Outlook2010�ŐV�K�ɐݒ肵���@�\(�d�l)�����o�[�W�����ō쐬���ꂽ�z���_�̎d�l��
���v���Ȃ��̂ŁA�܂�ȃP�[�X�ŕ����������N���Ă��܂������ł��B�@���̉͌��ɔ������Ă�����ɑ����̓I�Ȑ����łȂ��̂ŗ����o��
�Ȃ����̂ł��������A�d�����Ȃ��ƒ��߂ăA�h�o�C�X�ɏ]�����Ƃɂ��܂����B�@���A�C���|�[�g�����ł͋��o�[�W�����ō쐬�����T�u�z���_���A���̂܂܃C��
�|�[�g���Ă���邻���ł��B�@
�������E�E�E�������C���A�b�v�̐��i�Ȃ̂ɕςł��ˁB�@���������[���z���_�̓C���|�[�g���Ȃ���A�V�o�[�W�����Ŏg���Ȃ��̂ł���A�V�o�[�W������
�C���X�g�[���̍ۂɁA�u���[���z���_�̎w��v�ł͖����āu�C���|�[�g�v������I�����ɂ��ׂ��Ǝv���̂����E�E�E�B
������PC��Outlook2013���C���X�g�[�����Ă���̂ŁA����͂�����g�����Ƃɂ��āA����̓����[�g�f�X�N�g�b�v���g���đS�ă}�C�N���\�t�g�̃T�|�[�g
�f�X�N�̕��ɍs�Ȃ��đՂ��܂����B�@���ʁA�C���|�[�g���̂͐���ɏo���܂������AOutlook2013�Ń��[���̑��M���o���Ȃ��Ȃ��Ă��܂��܂����B�@Orz!
���ł�˂�I�@�Ǝv���Ă�����A���ɖ������̗l�ȃT�|�[�g�����Ă���}�C�N���\�t�g�@�T�|�[�g�f�X�N�I�@�@�E�B���X��\�t�g�̃X�p�����[���I�v�V����
��OFF�ɂ��āu����ς�ˁ[�B�@����ł��܂��s���܂����v�Ƃ̃R�����g�B�@�u���������A���ꂶ�።����ǁv�Ǝ��B�u���̖��̓E�B���X�\�t�g��Ђ̃T�|�[�g�f�X�N
�ɃG�X�J���[�V�������ĉ������v�@�ƃ}�C�N���\�t�g�B�@�u����ł͊Ԃɋ��܂ꂽ���͂ǂ��Ȃ�́H�v�ƌ����Ă��u�X�~�}�Z���B���̖��͎����ɂ͂ǂ��ɂ��Ȃ�܂���v
�ƃ}�C�N���\�t�g�B�@������Outlook2010�ŋ��z���_���g���Ă��鎞�̓X�p�����[���I�v�V�������I���ɂ��Ă����[�����M�͑��v�������̂ɁB�@
����ȏ㌾���Ă��A�S���҃��x������ł͉��Ƃ��Ȃ�Ȃ��B�@���߂ăE�B���X��\�t�g�x���_�[�̃z�[���y�[�W�ׂĂ݂�ƁA�ŐV�o�[�W����(Ver.6)�ł�
���̖��͊��m�̏�Q�Ƃ��ĉ��������[�X����Ă���B�@�����������̃o�[�W����(Ver.5)�ł͑Ή����Ă��Ȃ����A���m�ł����Ă��V�K�̏C���͂��Ă����
����B�uOutlook2013���g���̂ł���A�o�[�W�����U���w�����Ȃ����B�v�ƌ������ƂȂ�ł��ˁB�@�������������I�ɕ\�����Ă����Ηǂ��̂ɁE�E�E�E�B
����ς�}�C�N���\�t�g�̃w���v�f�X�N�ɓd�b���Ȃ��ł��̂܂g���Ă���Ηǂ������B�@���ʂȎ��Ԃ��g���Ă��܂����B
�߂������Ȃ��ꂪ�}���`�x���_�[����IT�@����g�����E�̎����Ȃ̂ł��B�@�ӔC�͈͂��n�b�L���������đS�̓I�Ȉ�ѐ����r�����Ă��܂��T�^��ł��B�@
����x���_�[�̒��̐^���͑��Ђ̐^���ł͂Ȃ��̂ŁA��Q���������Ă��b�����ݍ���Ȃ����Ƃ͑�R����܂��B
��ЋƖ��̏ꍇ�͐M���ł���SI�fer(�V�X�e���E�C���e�O���[�^�[�F�T�|�[�g���)�ƌ_�Ă����b�ɂȂ�̐��𐮂��Ă����Ȃ��ƁA�ƂĂ��|�����b�ł��B
�y�Q�l�z�_�u���o�C�g�Ƃ́H
�R���s���[�^�Œʏ�g�p����Ă���A�h���X���̏��ʂ͂P�o�C�g(8bit)�ƌ��߂��Ă��܂��B�@�����A�P�Ԓn������1�o�C�g(8bit)�̏�i�[����Ă��܂��B
����ł�1�o�C�g(8bit)�łǂꂾ���̏����̂ł��傤���H�@8bit���R���s���[�^�̗����o����Q�i�@�ŕ\������ƁG
�@Bit�ʒu) �@ �@8 7 6 5 4 3 2 1
�E�G�C�g�j 128 64 32 16 8 4 2 1 =>�S��������255; ����1�o�C�g�� 0����255�̒l���\���ł���B
�@�@2�i�@�\���� 0 1 1 �@ 0 1 1 0 1 =>�����10�i�@�ɒ����� 64+32+8+4+1=109 �ƂȂ�܂��B
�Ƃ���ʼnp�����Ə�p�����L��������\������̂ł���@�啶��26��A������26��A�@����10��ƋL���Ȃ̂�256��ނ̕\�����o����Ώ[���ł��B
�̂̃e���^�C�v(�p��̓d�M)��128�������Ώ\���ł������̂�1�o�C�g���Vbit�Ƃ��Ĉ����A�c���1bi���͒ʐM�G���[�̌��o�̂��߂Ɏg���Ă��܂���(Even Parity�j
�������A�R���s���[�^�����E���Ŏg����l�ɂȂ������݂�,���{������߂Ƃ��Ē����ꓙ�̊����A�n���O�������A�A���r�A�����@���X�̃}���`�i�V���i������Ή���
�v�����o�ė��܂����B�@�����̌�������{��Ɠ��l�ɕ���������R����̂�8�r�b�g(256��)�ł͖����A2�{��2�o�C�g(16bit�F65536��)���g���K�v������܂��B�@
(�r�b�g����2�{��16�r�b�g���g����Ε\���ł���l�͔{�ł͂Ȃ��āA1�o�C�g�ŕ\���ł���l�ł���256�̍X��256�{�ƂȂ�A65536��̕������g���邱�ƂɂȂ�܂�)�@
��{�I�ɂ͂���ő�R����e���̃��j�[�N�ȕ����\��������̎w�肳���s�Ȃ��Ή\�ƂȂ�܂����B �@�ʂ̕\��������Ίe���ꖈ�ɍő�65536��̕������g�p
�\�ƂȂ�̂ŁA�f�[�^�̎n�߂̕����ɂǂ̌���ł��邩��錾������K�v������܂��B�@
�����ŁA�R���s���[�^�̃f�[�^�����̐��E�ł͓��ʂȎ��ʃR�[�h���f�[�^�[�̓��ɂ���JIS�K�i�Ƃ��A���r�A��Ƃ�UTF-8�Ƃ�US-ASCII���X�̋��(�錾)�����Ă��܂��B�@
���ꂪ�G���R�[�h�^�f�R�[�h�ƌĂ�鎯�ʕ����ł��B�@�G���R�[�h�͂����Ō���1�o�C�g�܂���2�o�C�g�́w�R���s���[�^�f�[�^�x���w�����f�[�^�x�ɕϊ����邱�ƁA�f�R�[�h�͂��̋t
�̑���������܂��B�@
(���F�G���R�[�h�^�f�R�[�h�͈Í��y�ѓd�q��H�̋@�\�������p��Ƃ��Ă��L���g���Ă��܂��B�@�A���A�Í����̏ꍇ�̓G���N���v�V����/�f�N���v�V�����̕������m�ł�).
��ʓI�ɃG���R�[�h�̎�ނ͐�̃G���R�[�h�̑I�𑀍�ŎQ�Ƃł��܂����A���ɂ�����Ȃ����炢�̎�ނ����邵�A�K�i�������ύX����Ă��܂��B
����Ȗ�ŁA���[���\�t�g���������G���R�[�h�������s�Ȃ��͎̂��ɑ�ςł��B�@�N��������Ȃ����肪���M�������[���̃G���R�[�h���A������ύX����Ă������M�̎���
�Ԉ�����\�������Ă��܂��܂��B�i���������j�@���̗l�Ȏ��Ԃ�h�~���邽�߂ɂ��̃G���R�[�h�͐��E�I�ɊǗ�����Ă��锤�ł����A��͂�R��������悤�ł��B
�y2�o�C�g�����ɂ��āz
http://www.sophia-it.com/content/2%E3%83%90%E3%82%A4%E3%83%88%E6%96%87%E5%AD%97
